

cyber/verso exists to look, with a critical and analytical eye, at the intersection of technology, economy and digital society. The longer essays published on this blog are the space where I try to read what things mean: technology as a choice about power, European autonomy in the age of digitalisation through international cooperation rather than isolation, digital public infrastructure like the EUDI Wallet and the Digital Euro, identity, currency, policy, AI as a tool of governance. Before the analysis, though, there is something I have done every morning for years: I read the news on these same themes, decide what actually matters, and distil it into a synthesis. Out of this "unhealthy" habit, and my wish to keep it while cutting down its toll on my day, the new /brief section was born. Let me confess the motive right away: it all began as the search for a way, one that may strike most people as rather "convoluted", to avoid reading more than six hundred articles every morning before coffee.
Before getting into this "novelty", though, I want to stress a fundamental distinction between the things this blog produces. In the essays there is my voice, the argument, the thesis. In the brief there is none of that. The brief is a synthesis of the news organised around a focus, with no commentary of mine. It is the raw signal, the same one some of the essays published here may grow out of, but which, in the /brief section, is kept deliberately free of any opinion or commentary.
Commentary is a human act, and I keep it where it belongs.
The brief ships every day here: cyberverso.net/brief.
Why I did it, and what I learned
As I said, the goal was never the brief itself, but the exercise behind it. I have been building digital infrastructure for a while, which did not stop me discovering how little I knew about actually putting an AI agent together. So instead of studying it in the abstract, I applied it to a concrete, repetitive task I already did by hand, with my own sources. I automated it and decided to publish it, both the output and the method. Not because it is special: precisely because it is mundane, and therefore an honest test bench.
What struck me most in this experiment is not the outcome, the brief itself, but what the exercise says about how software gets built today. "Deciding what matters in a news item" is not a problem with a formula. Until recently a judgment like that was either left "to the head", or it required writing a pile of brittle rules that aged very fast. Now you can break it into stages, hand each one to a model and make it work, in a few evenings rather than months. That is the real change: I do not just write code faster, I can approach in a structured way problems that had no linear solution before, and that I therefore could not automate at all. It is something I have been mulling over for a while and would like to devote a separate article to: how AI is changing not just the speed but the very way we develop software and organise people's work.
Where AI actually helps

Going back to the "unhealthy" morning habit I started from, it has to be said that the bottleneck was never writing the synthesis of what I read, but the volume of reading and the consistency of judgment. You can only read so many sources before the day starts with its work and its routines, and past the thirtieth story attention drops and the selection criteria shift without your noticing.
I say this from direct experience.
This is exactly where AI helps: it reads everything, every day, and applies the same editorial criteria without fatigue and without drift. It does not replace judgment, it multiplies it on the part that is mechanical but cognitively expensive: filtering a huge flow against a stable lens, the cyber/verso one, and distilling it into a faithful synthesis organised around a focus. The value is not opinion, which stays human and is deliberately absent, but synthesis at scale. AI is good precisely where I was the limit, which is at once useful and (at least a "smidge") humbling.
The architecture: four stages
The system has four logical stages.
I tell them in full, details included, because that is where you see where the AI is used and where ordinary deterministic code is used instead; a non-technical reader can skim the numbers without losing the thread.
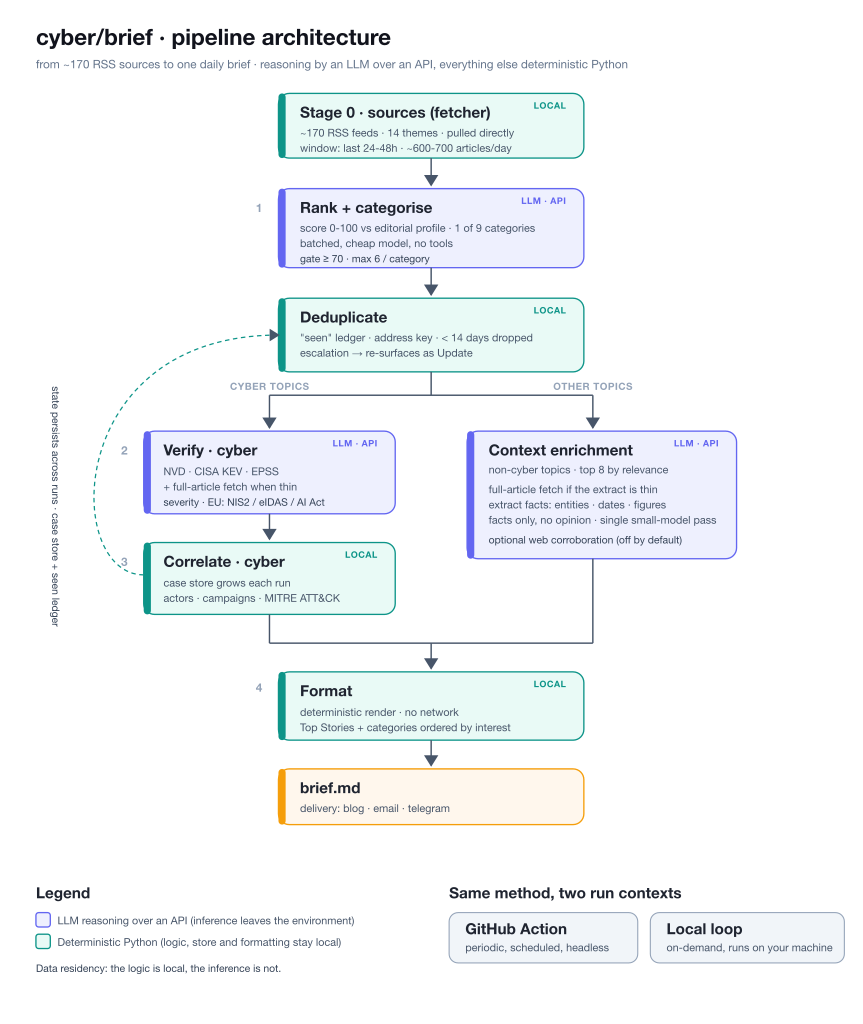
Stage 0, the sources. Upstream sits a fetcher that pulls the RSS feeds directly from the source, with no middleman and no third-party service: the source list is a hand-curated OPML file, the sources I have selected over the years and keep updating, and the fetcher queries each feed at its origin. There are about 170 sources organised into 14 themes (intelligence and CTI, AI and cybersecurity, vulnerabilities and exploits, policy and regulation, digital identity, digital euro, US/EU/China technology, defence, and more). The lookback window is limited to the last 24-48 hours, so the brief stays on the day's news: on a typical day the fetcher gathers several hundred articles (around 600-700). That is the raw flow stage 1 has to "sift".
Stage 1, ranking the news. This is what separates a useful brief from a noise aggregator. A cheap, high-recall judge gives every candidate a score from 0 to 100, not for generic newsworthiness but against the cyber/verso editorial profile: it rewards technology policy, power and sovereignty moves across the US, EU and China, AI governance, and cyber events with real impact; it scores down (under 40) routine noise, individual CVE advisories, patch notes, vendor marketing, launches, funding rounds. Along with the score it assigns exactly one of the nine categories that map my themes (US & Technology, EU & Technology, China & Technology, AI & Power, Cybersecurity & Threats, Threat Intelligence, Defence & National Security, Digital Sovereignty & Identity, Quantum/Cryptography & CBDC) and a one-line reason.
Behind the scenes, three choices make the difference. The judge sees every fetched item, so it is designed to cost little: it scores candidates in groups (around twenty at a time, several groups in parallel) with a small, fast model, so the criteria stay the same across the whole set. Then the gate: only items scoring 70 or above are promoted, at most six per category, so no single crowded topic dominates the brief. The expensive enrichment is spent only on the promoted few, never on the hundreds of candidates.
A further step follows, deduplication, the discarding of what has already been said. Between stage 1 and stage 2 there is a step that keeps the brief honest: a check against a ledger of stories already published. Each story is recognised by its address, cleaned of the tracking parameters that would otherwise make an already-seen item look "new"; if the address is missing, the title is used. If a story already appeared in the last 14 days, it is dropped from the new brief: no echo of the same headlines day after day. The one exception is when correlation flags an escalation, a case that genuinely advanced: then the story is allowed back in, marked as an Update. The ledger keeps a story's first appearance, its last, and how many times, and prunes itself after 120 days. It is pure code and runs anywhere.
Stage 2, verification (cyber topics only). Threats need deeper fact-checking: the agent looks up the CVE on NVD, checks the CISA KEV catalogue for active exploitation, pulls the EPSS score and, when the extract is too thin, fetches the full article. It produces a structured picture, with EU relevance read through the applicable frameworks (NIS2, eIDAS, AI Act).
For the other topics, a lighter enrichment. Non-cyber stories have no CVE to verify, so they get a different, less costly treatment: for the few most relevant items across categories (at most eight), if the feed extract is too thin the agent fetches the full article and, in a single pass with a small model, extracts the verifiable facts from it, the entities named, dates, key figures. Facts only, no opinion. There is also an optional corroboration, off by default: a single web search to confirm one key claim (a date, a figure, who said what), which shows up in the brief as a confirmation mark or a mismatch flag. Every network call is logged, because it counts for data residency.
Stage 3, correlation. Each signal is matched against a store that grows with every run, so links between actors and campaigns sharpen over time, and it is also what feeds the escalation signal the deduplication uses. It is accumulating memory, not commentary.
Stage 4, formatting. Each promoted item becomes a record carrying its score and category. The renderer builds a dynamic brief: a short editorial synthesis, a Top Stories lead, then only the categories that have news, ordered by the day's interest. This stage is pure code, deterministic, no network.
Two ways to run it
The reasoning engine is an LLM reached over an API; everything else is deterministic Python scripts that act as scaffolding, fetch the feeds, apply the deduplication and render the template. The same four-stage method runs in two contexts, and this is the part that taught me the most.
For periodic execution I use a GitHub Action: a scheduled workflow, independent of my laptop, that pulls the sources with the fetcher, runs ranking, verification, correlation, deduplication and rendering, publishes the brief and persists state (the case store and the seen-news ledger) to a dedicated branch, so the memory survives from one run to the next.
For on-demand execution I use a local loop instead: the same four-stage method runs on my own machine with a single command, and nothing leaves the environment except the model inference over the API. It is the control context, useful for tuning the parameters, giving a single day a different focus, or simply keeping everything local.
The design choices
The two contexts, GitHub Action and local loop, are not just two pieces of infrastructure: they are the same method run in different ways. The first automates it and makes it independent of my machine; the second leaves me in control and keeps everything local except the inference. That is the lesson: where unattended automation matters, the scheduled pipeline wins; where control, tuning and local residency matter, the loop on my own machine wins.
Another deliberate choice was to spend the expensive compute only where it counts, on the funnel principle: many candidates in, very few reaching the costly stages.
Finally, data residency, unavoidable when working through a European lens and fitting for what I write about. Orchestration, the store and formatting stay local; model inference and the enrichment calls leave toward the API and mostly US sources. The logic is local, the inference is not.
A caveat: a filter needs checking

A word of caution, so the enthusiasm does not make me forget the craft. A filter like this is not neutral: it decides what I see and, more importantly, what I do not. Handing it the judgment and then trusting it blindly is the fastest way to introduce a bias and never notice. The risk is not theoretical: a criterion that favours certain topics or sources, repeated every day, can slowly narrow the view of the subject precisely while it seems to widen it.
That is why verification cannot be a one-off. It needs an ex-ante method, one that lets me know what I expect the filter to promote and to drop before I run it, and an ex-post one, that lets me spot-check what was actually kept out, every so often and not just on the first pass. It is the necessary counterweight to automation: without a periodic check it is laziness, not the model, that distorts the signal. Automating the reading does not mean automating the trust.
What I take away
Automating work I used to do by hand did not erode my expertise, quite the opposite: it forced me to rebuild the method I followed "on instinct" and write it down step by step, something I had put off for years. The commentary stays in the essays; the effort of reading everything, every day, against the same yardstick, I happily leave to the code. The thing that matters here is not my brief: it is that a task I thought impossible to automate, because it needs judgment and not a formula, turned out to be breakable into a few simple pieces, each within a model's reach. That is the real shift, and it is happening fast.
The next enemy is already lying in wait, and it is shaped like my inbox: dozens of emails a day staring me down. If a brief that summarises my emails instead of the news shows up here in a few weeks, you will know I lost that battle too. In the meantime, at least I drink my coffee in peace.