

cyber/verso nasce per guardare con occhio critico e analitico l'intersezione tra tecnologia, economia e società digitale. Gli articoli “più estesi” pubblicati su questo blog sono lo spazio dove provo a leggere il senso delle cose: la tecnologia come scelta di potere, l'autonomia europea nell’era della digitalizzazione attraverso la cooperazione internazionale e non l'isolamento, le infrastrutture pubbliche digitali come EUDI Wallet e Euro Digitale, l'identità, la moneta, la policy, l'AI come strumento di governance. Prima dell'analisi, però, c'è una cosa che faccio ogni mattina da anni: leggo le notizie su questi stessi temi, decido cosa conta davvero e ne ricavo una sintesi. Da questa “insana” abitudine, e dal mio desiderio di conservarla riducendone al tempo stesso l’impatto sulla mia giornata, nasce la nuova sezione /brief. Confesso subito il movente che mi ha portato a concepire questa rubrica: tutto è cominciato come la ricerca di un modo, che forse apparirà alquanto “contorto” agli occhi dei più, per non dovermi leggere ogni giorno oltre seicento articoli prima del caffè.
Prima di entrare nel merito di questa “novità”, tuttavia, ci tengo a sottolineare una distinzione fondamentale fra i prodotti di questo blog. Negli articoli c'è la mia voce, l'argomento, la tesi. Nel brief no. Il brief è una sintesi delle notizie organizzata intorno a un focus, senza miei commenti. È il segnale grezzo, lo stesso da cui poi possono nascere alcuni degli articoli qui pubblicati, ma che, nella sezione /brief, viene mantenuto deliberatamente privo di qualsivoglia opinione o commento a corredo.
Il commento è un atto umano e lo tengo dove deve stare.
Il brief esce ogni giorno qui: cyberverso.net/brief.
Perché l'ho fatto, e cosa ho capito
Come detto, l'obiettivo non era il brief in sé, ma l'esercizio che ci sta dietro. Costruisco infrastrutture digitali da un po', cosa che non mi ha impedito di scoprire quanto poco sapessi di come si mette insieme davvero un agente AI. Così, invece di studiarlo in astratto, l'ho applicato a un compito concreto e ripetitivo che già facevo a mano, con le mie fonti. L'ho automatizzato e ho deciso di pubblicarlo, sia il risultato sia il metodo. Non perché sia speciale: proprio perché è banale, e quindi un onesto banco di prova.
La cosa che mi ha colpito di più in questo esperimento non è l’esito, il brief appunto, quanto piuttosto quello che l'esercizio dice su come si sviluppa software oggi. "Decidere cosa conta in una notizia" non è un problema con una formula. Fino a poco tempo fa un giudizio del genere o lo lasciavi “alla testa”, o richiedeva la scrittura di una montagna di regole fragili e soggette a rapidissima obsolescenza. Oggi puoi scomporlo in fasi, affidarne ciascuna a un modello e farlo funzionare, in qualche serata invece che in mesi. È questo il cambiamento vero: non scrivo solo codice più in fretta, posso affrontare in modo strutturato problemi che prima non avevano una soluzione lineare, e che quindi non potevo automatizzare affatto. È un aspetto su cui sto ragionando da un po’ e a cui vorrei dedicare un articolo a parte: come l'AI stia cambiando non solo la velocità, ma il modo stesso di sviluppare software e di organizzare il lavoro delle persone.
Dove l'AI serve davvero

Rispetto alla mia “insana” abitudine mattutina da cui sono partito, c’è da dire che il collo di bottiglia non è mai stato scrivere la sintesi delle notizie che leggevo, quanto il volume di lettura e la costanza del giudizio. Si riesce a leggere solo un certo numero di fonti prima che la giornata inizi con i suoi impegni lavorativi e le sue routine, e dopo la trentesima notizia l'attenzione cala e i criteri di selezione si alterano, senza accorgersene.
Lo dico per esperienza diretta.
È esattamente qui che l'AI aiuta: legge tutto, ogni giorno, e applica lo stesso criterio editoriale senza stanchezza e senza deriva. Non sostituisce il giudizio, lo moltiplica sulla parte meccanica ma cognitivamente costosa: filtrare un flusso enorme rispetto a una lente stabile, quella di cyber/verso, e distillarlo in una sintesi fedele organizzata intorno a un focus. Il valore non è l'opinione, che resta umana ed è volutamente assente, ma la sintesi su larga scala. L'AI è brava proprio dove io ero il limite, il che è insieme utile e (almeno un “tantinello”) umiliante.
L'architettura: quattro fasi
Il sistema ha quattro fasi logiche.
Le racconto per intero, dettagli compresi, perché è lì che si vede dove viene utilizzata l'AI e dove invece viene utilizzato il normale codice deterministico; chi non è del mestiere può scorrere i numeri senza perdere il filo.
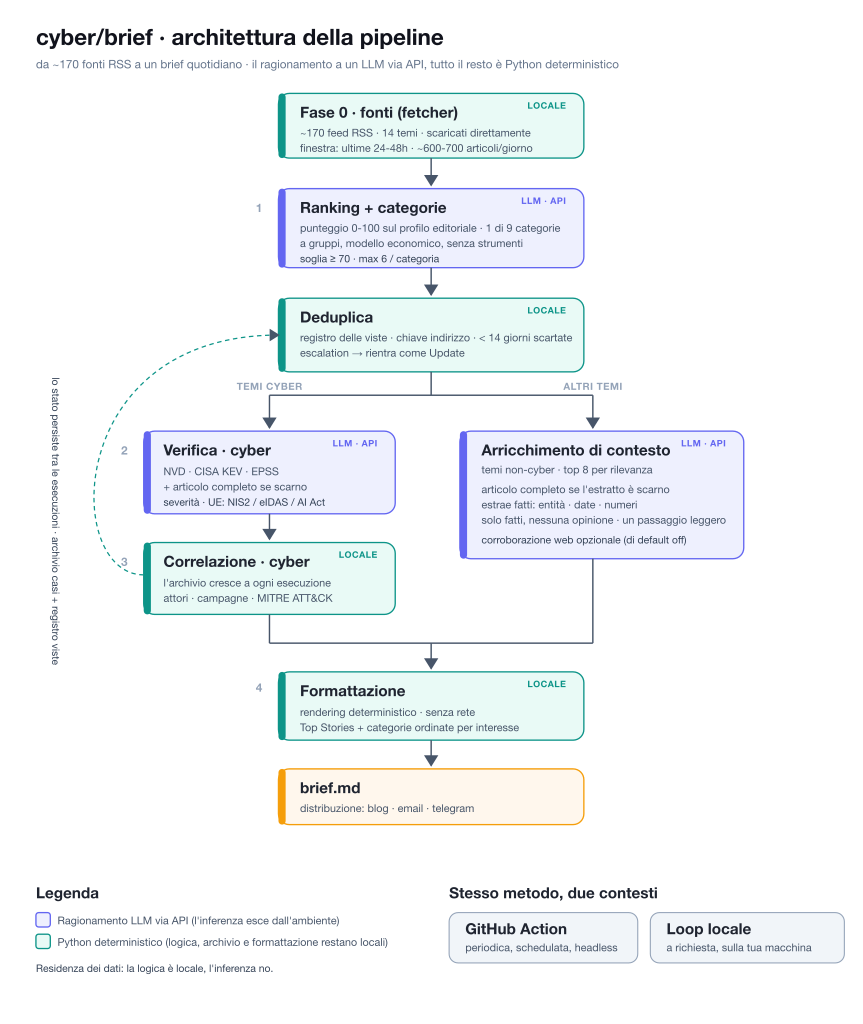
Fase 0, ovvero: le fonti. A monte c'è un fetcher che scarica i feed RSS direttamente dalla sorgente, senza intermediari né servizi terzi: la lista delle fonti è un file OPML curato a mano, sono le fonti che ho selezionato negli anni e continuo ad aggiornare, e il fetcher interroga ogni feed alla sua origine. Sono circa 170 fonti organizzate in 14 temi (intelligence e CTI, AI e cybersecurity, vulnerabilità ed exploit, policy e regolazione, identità digitale, euro digitale, tecnologia di USA/UE/Cina, difesa, e altri). La finestra di ricerca è ristretta alle ultime 24-48 ore, così il brief resta sulle notizie del giorno: in una giornata tipica il fetcher raccoglie diverse centinaia di articoli (intorno a 600-700). È questo il flusso grezzo che la fase 1 deve “setacciare”.
Fase 1, il ranking delle notizie. È la parte che fa la differenza tra un brief utile e un aggregatore di rumore. Un giudice economico e ad alto recall assegna a ogni candidato un punteggio da 0 a 100, non per "notiziabilità" generica ma rispetto al profilo editoriale di cyber/verso: premia policy, potere e sovranità tecnologica tra USA, UE e Cina, la governance dell'AI, gli eventi cyber con impatto reale; penalizza (sotto 40) il rumore di routine, singoli avvisi CVE, patch note, marketing di prodotto, lanci, round di finanziamento. Insieme al voto assegna una sola delle nove categorie che mappano i miei temi (USA & Tecnologia, UE & Tecnologia, Cina & Tecnologia, AI & Potere, Cybersecurity & Minacce, Threat Intelligence, Difesa & Sicurezza Nazionale, Sovranità Digitale & Identità, Quantum/Crittografia & CBDC) e una riga di motivazione.
Dietro le quinte, tre scelte fanno la differenza. Il giudice vede ogni notizia recuperata, quindi è disegnato per costare poco: valuta i candidati a gruppi (una ventina per volta, più gruppi in parallelo) con un modello piccolo e veloce, così il criterio resta lo stesso su tutto l'insieme. Poi scatta la soglia: solo gli elementi con punteggio pari o superiore a 70 vengono promossi, al massimo sei per categoria, per non far dominare il brief da un singolo tema affollato. L'arricchimento costoso si spende solo sui pochi promossi, mai sulle centinaia di candidati.
Segue un passaggio ulteriore: “Deduplica”, ovvero lo scarto di ciò che è già stato detto. Tra la fase 1 e la fase 2 c'è un passaggio che consente di mantenere il brief “onesto”: il vaglio attraverso un registro delle notizie già pubblicate. Ogni storia è riconosciuta dal suo indirizzo, ripulito dai parametri di tracciamento che altrimenti farebbero sembrare "nuova" una notizia già vista; se l'indirizzo manca, viene utilizzato il titolo. Se una notizia è già comparsa negli ultimi 14 giorni, viene scartata dal nuovo brief: niente eco degli stessi titoli giorno dopo giorno. L'unica eccezione è quando la correlazione segnala un'escalation, un caso che è davvero avanzato: allora la storia rientra, marcata come Update. Il registro tiene traccia della prima apparizione di una storia, dell'ultima volta che è apparsa e di quante volte, e si auto-pota dopo 120 giorni. È codice puro, gira ovunque.
Fase 2, la verifica (solo temi cyber). Sulle minacce serve un controllo dei fatti più profondo: l'agente cerca la CVE su NVD, controlla il catalogo CISA KEV per lo sfruttamento attivo, recupera lo score EPSS e, quando l'estratto è troppo scarno, scarica l'articolo completo. Ne ricava un quadro strutturato, con la rilevanza UE letta attraverso i framework applicabili (NIS2, eIDAS, AI Act).
Per gli altri temi, un arricchimento più leggero. Le notizie non-cyber non hanno una CVE da verificare, quindi ricevono un trattamento diverso e meno costoso: per i pochi item più rilevanti (al massimo otto), se l'estratto del feed è troppo scarno l'agente scarica l'articolo completo e ne estrae, in un solo passaggio e con un modello semplice, i fatti verificabili: entità citate, date, numeri chiave. Solo fatti, nessuna opinione. C'è anche una corroborazione opzionale, spenta di default: una singola ricerca web per confermare un'affermazione chiave (una data, una cifra, chi ha detto cosa), che nel brief compare come un segno di conferma o un avviso di incongruenza. Ogni chiamata di rete viene registrata, perché conta per la residenza dei dati.
Fase 3, la correlazione. Ogni segnale viene confrontato con un archivio che cresce a ogni esecuzione, così i collegamenti tra attori e campagne si affinano nel tempo, ed è anche ciò che alimenta il segnale di escalation usato dalla deduplica. È memoria che si accumula, non un commento.
Fase 4, la formattazione. Ogni elemento promosso diventa un record con punteggio e categoria. Il renderer costruisce un brief dinamico: una sintesi editoriale di poche frasi, un blocco Top Stories e poi solo le categorie con notizie, ordinate per interesse del giorno. Questa fase è codice puro, deterministica, senza rete.
Due modi di farlo girare
Il motore di ragionamento è un LLM raggiunto via API; tutto il resto è script Python deterministici che fanno da impalcatura, recuperano i feed, applicano la deduplica e rendono il template. Lo stesso metodo a quattro fasi gira in due contesti, ed è questa la parte che mi ha insegnato di più.
Per l'esecuzione periodica uso una GitHub Action: un workflow schedulato, indipendente dal mio portatile, che scarica le fonti con il fetcher, esegue ranking, verifica, correlazione, deduplica e rendering, pubblica il brief e persiste lo stato (archivio dei casi e registro delle notizie viste) su un branch dedicato, così la memoria sopravvive tra un'esecuzione e l'altra.
Per l'esecuzione estemporanea, a richiesta, uso invece un loop locale: lo stesso metodo a quattro fasi gira sulla mia macchina con un comando, e nulla esce dall'ambiente tranne l'inferenza del modello via API. È il contesto del controllo, utile per mettere a punto i parametri, dare un focus diverso a una singola giornata, o semplicemente tenere tutto in locale.
Le scelte di design
I due contesti, GitHub Action e loop locale, non sono solo due infrastrutture: sono lo stesso metodo eseguito in modi diversi. Il primo lo automatizza e lo rende indipendente dalla mia macchina; il secondo mi lascia il controllo e tiene in locale tutto tranne l'inferenza. La lezione è proprio questa: dove conta l'automazione senza presidio vince la pipeline schedulata, dove contano controllo, messa a punto e residenza locale vince il loop sulla mia macchina.
Un'altra scelta deliberata è stata spendere il calcolo costoso solo dove serve, secondo il principio del filtro a imbuto: tanti candidati in entrata, pochissimi che arrivano alle fasi care.
Infine la residenza dei dati, inevitabile lavorando in chiave europea e coerente con quello di cui scrivo. Orchestrazione, archivio e formattazione restano locali; l'inferenza del modello e le chiamate di arricchimento escono verso l'API e fonti perlopiù statunitensi. La logica è locale, l'inferenza no.
La cautela: un filtro va verificato

Un avvertimento, perché l'entusiasmo non mi faccia dimenticare il mestiere. Un filtro come questo non è neutro: decide cosa vedo e, soprattutto, cosa non vedo. Affidargli il giudizio e poi fidarsi a scatola chiusa è il modo più rapido per introdurre un bias e non accorgersene mai. Il rischio non è teorico: un criterio che premia certi temi o certe fonti, ripetuto ogni giorno, può restringere lentamente lo sguardo sull’oggetto di indagine proprio mentre sembra ampliarlo.
Per questo la verifica non può essere una tantum. Serve un metodo di valutazione ex-ante, che consenta di sapere cosa mi aspetto che il filtro promuova e scarti prima di lanciarlo, ed ex-post, che permetta di ricontrollare a campione cosa è stato effettivamente tenuto fuori, di tanto in tanto e non solo al primo giro. È il contrappeso necessario all'automazione: senza un controllo periodico è la pigrizia, non il modello, a distorcere il segnale. Automatizzare la lettura non significa automatizzare la fiducia.
Cosa porto a casa
Automatizzare un lavoro che facevo a mano non mi ha sottratto competenza, anzi: mi ha costretto a ricostruire il metodo che seguivo “ad istinto” e a scriverlo passo per passo, una cosa che rimandavo da anni. Il commento resta negli articoli; la fatica di leggere tutto, ogni giorno, con lo stesso metro, la lascio volentieri al codice. La cosa che conta qui non è il mio brief: è che un compito che credevo difficile o almeno dispendioso da automatizzare, perché richiede un giudizio e non una formula, si è rivelato scomponibile in pochi pezzi semplici, ciascuno alla portata di un modello. Questo è il vero cambio di passo, e succede in fretta.
Il prossimo nemico è già in agguato, e ha la forma della mia casella di posta: decine di email al giorno che mi fissano con aria di sfida. Se tra qualche settimana qui comparirà un brief che riassume le mie email invece delle notizie, saprete che ho vinto anche quella battaglia. Nel frattempo, almeno il caffè lo bevo in pace.